Scaling beyond 65k reverse proxy connections on localhost
by @pseudonom on January 21, 2016
Trouble in paradise
One fine day, we noticed a number of connect() to 127.0.0.1:3004 failed (99: Cannot assign requested address) in our NGINX logs while connecting to the upstream application server. Those errors cast the plateau in the following chart in a more menacing light:
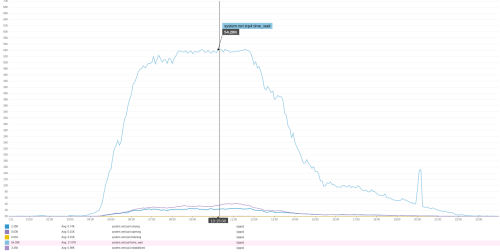
That flat peak wasn’t an artifact of our traffic patterns; it was due to technical limitations on our end. The chart makes it quite obvious that we’re filling up with TIME_WAIT connections in the NGINX <-> local application binary phase.
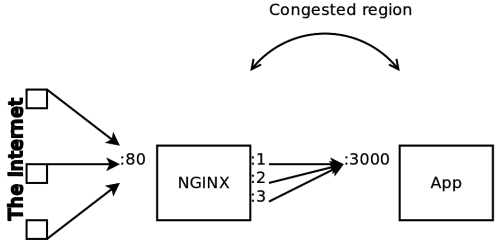
TIME_WAIT and other ameliorations
TIME_WAIT
Given the plateuing chart, we began our search for a fix with TIME_WAIT.
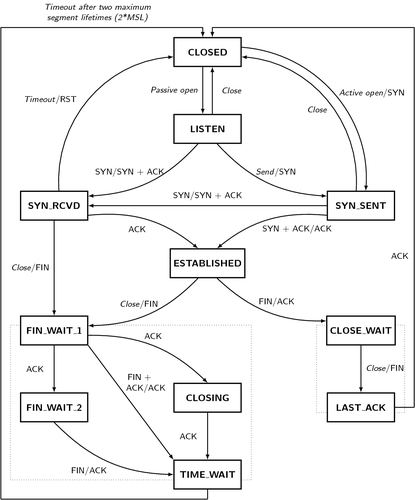
TIME_WAIT is a part of the TCP state machine entered by the computer which initiates the connection closure in order to ensure clean closure. But do we really have to wait there 60 whole seconds? Decreasing that number ought to decrease the number of outstanding connections proportionately.
It turns out that, yes, it does have to be 60 seconds. At least on Linux. It’s hardcoded in the kernel. (This blog post is a good resource for more about TIME_WAIT on Linux.)
Retrospectively, it also seems that sysctl net.ipv4.tcp_tw_reuse = 1 would have been a safe and effective way to reduce the number of NGINX <-> app TIME_WAIT connections. (Since it only applies to outbound connections, it would have had no effect on connections from users.) But in the moment, we missed this and pushed on to another solution.
Ephemeral ports
If we can’t decrease the number of connections, maybe we can increase the cap? What’s the limit anyway?
It turns out that the Linux kernel stores all active connections in a connection table. In this table, connections are identified by the quadruplet (client_ip, client_port, server_ip, server_port). Each connection quadruplet must be unique. If not, we get connection errors like above. This reveals why the problem was at the reverse proxy stage. In the NGINX <-> app connections phase, the client IP was always identical. In the public <-> NGINX phase, the client IP varied widely.
Ordinarily, in that quadruplet, client_ip (who’s trying to connect), server_ip (who they’re trying to connect to) and server_port (what service they’re trying to connect to) are fixed. This means that client_port is our only lever for deduplicating connections in the connection table. This client port is also know as the ephemeral port and is configurable via net.ipv4.ip_local_port_range. On Ubuntu 14.04, this defaults to port 32768–61000 which means we can only have 28232 simultaneous connections to a given IP and port. We bumped this range to 15000–65000 (limited from below by our desire to avoid collisions with reserved ports and from above by the max of a 16 bit unsigned integer). But given our growth , a 77% increase in allowable connections only kicked the can down the road a bit.
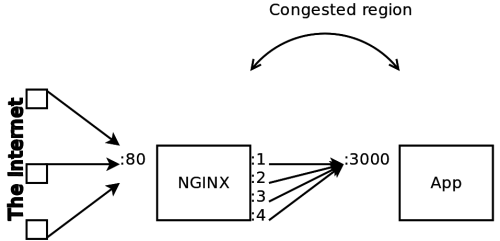
A better solution
Could we do better? Yes. While our setup meant that all client IPs were identical, the fact that our destination was on the same computer opened a new possibility with server IPs. We had configured NGINX to proxy to :3000 on 127.0.0.1. But all IPs on the 127.0.0.0/8 subnet refer to the local loopback! By adding:
upstream app {
server 127.0.0.1;
server 127.0.0.2;
server 127.0.0.3;
…
}
to the NGINX config, we can reach our application via a huge number of IPs. This increased our number of allowable reverse proxy connections by a factor of almost 17 million!
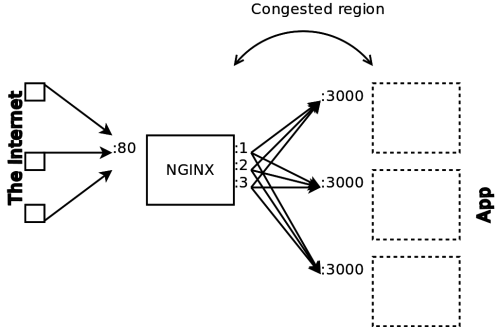
A final solution
“Load-balancing” to multiple virtual IPs for the loopback interface is a fine solution if you HAVE to stick to using TCP for your localhost communication. An even better, however less documented, solution is to bypass the OS’s TCP stack altogether and instead leverage UNIX domain sockets.
UNIX sockets have the great property of not having to worry about ephemeral ports, about congestion control and all other tuning options that are critical for a healthy TCP exchange. Assuming the application you are reverse-proxying to can read from them, you can send your HTTP requests to it through the socket instead of using TCP.
What kind of results did we see from it? We completely stopped having to worry about running out of ports, and that was the main goal. Performance wasn’t something that we had been struggling with, but the switch did bring the pleasant upside of doubling our throughput when benchmarking.
References
Unsurprisingly, high performance tuning isn’t a large concern for the majority of the developer population. It’s a rather rarifed problem to have. Most of the cloud application performance wisdom is locked away at larger organizations. There are however a few folks out there who are generous enough to share their hard-earned learnings, and these were the resources that helped us the most when dealing with this issue:
- http://engineering.chartbeat.com/2014/01/02/part-1-lessons-learned-tuning-tcp-and-nginx-in-ec2/
- http://engineering.chartbeat.com/2014/02/12/part-2-lessons-learned-tuning-tcp-and-nginx-in-ec2/
- Netflix’s Brendan Gregg’s excellent book on Systems Performance: http://www.brendangregg.com/sysperfbook.html
- TCP/IP Illustrated: https://en.wikipedia.org/wiki/TCP/IP_Illustrated