Announcing Stackctl
by @pbrisbin on May 20, 2022
Today we’re excited to formally announce our latest open-source tool,
stackctl. This tool has unlocked GitOps at Freckle and
transformed the haphazard handling of our Infrastructure As Code into
something reliable, re-playable, and highly auditable. In this post, I’ll
describe how Stackctl came to be and show how it can improve your CloudFormation
operations too.
How It Works
When we make changes to infrastructure resources at Freckle, we follow the same process as any other development we do.
We propose the change as a Pull Request (PR) in a GitHub repository. In this case, a tweak to a Role in a CloudFormation template for shared IAM resources:
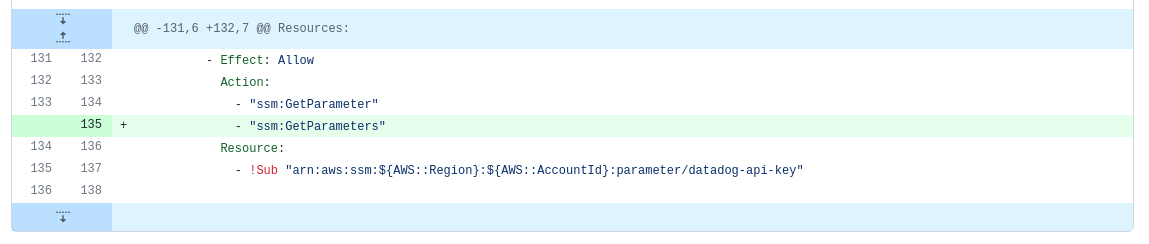
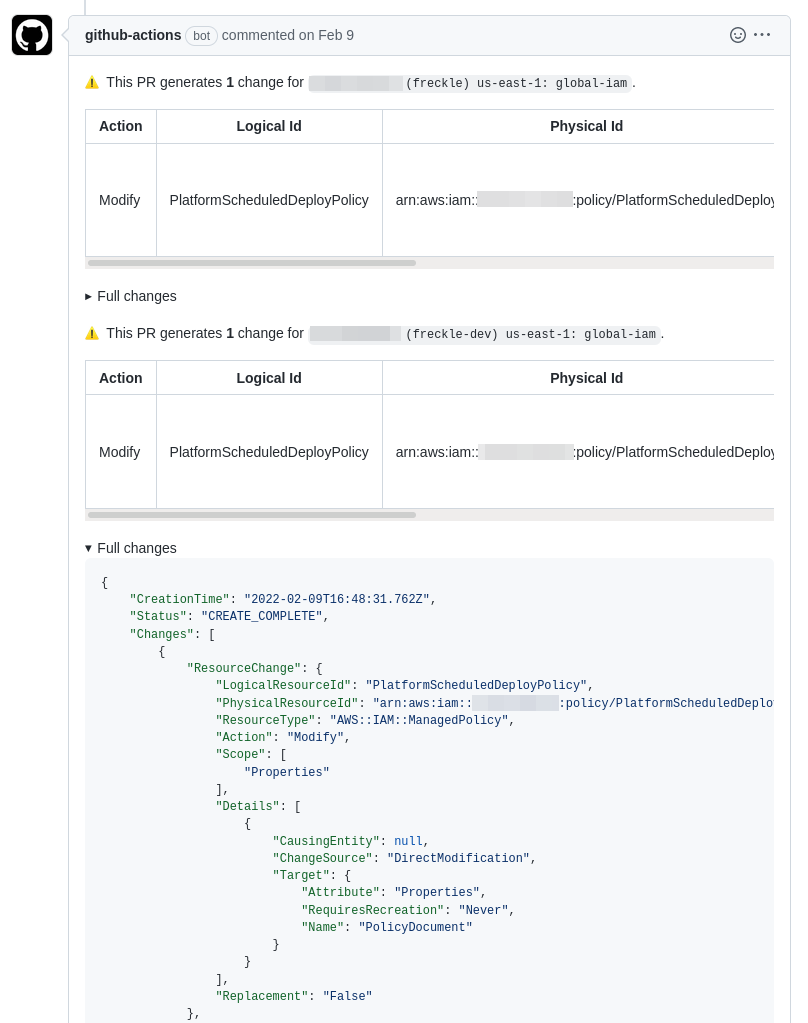
We run automation to help validate the PR. In this case, a GitHub Action uses
stackctl changes to create ChangeSets against all Stacks that use this
template, format their details, and add that as a comment on the PR:
We get review– the code and the comment in this case –to decrease the chances of mistakes and raise visibility of the changes:

Once Approved and merged, we automatically deploy the changes when they hit
main. In this case, that means deploying with stackctl deploy:
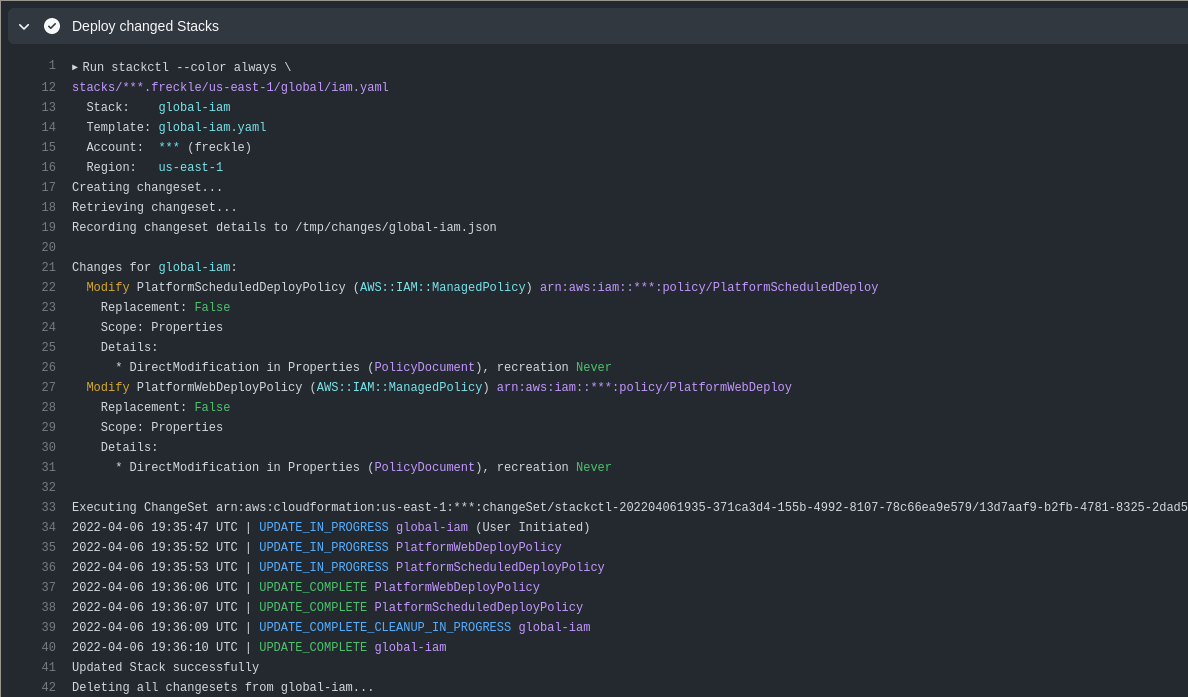
We unlocked the workflow above by building a tool called Stackctl, which manages on-disk representations of our CloudFormation Stacks that we call Stack Specifications. Then we wrapped the tool in GitHub Actions1 to add visibility and automation by handling infrastructure changes entirely through Pull Requests.
We arrived at this approach through a long process of incremental improvement on top of existing workflows and deployed Stacks that we couldn’t disrupt. The journey was indirect, but we ended up with a system that works well for our App teams and our Platform team. And we’re thankful to be able to open source the core of it for anyone to use and improve.
Where We Began
When I joined Freckle 4 years ago, we already had a great operational foundation. We were using IaC, and deploying small changes frequently.
Still, there was much to be improved:
- We deployed manually every afternoon, from someone’s laptop
- We had no real Incident Response processes
- We had a single “Ops Person”, who owned all of this in isolation
Over the past 4 years, the team has leveled-up massively in this area. We have an expanded suite of monitoring and observability tools, defined Service Level Objects (SLOs) and robust practices for handling Incidents when they’re violated; we continually and automatically deploy up to 30 times a day; and we’ve both expanded the team and instilled a culture of “Runbooks for everything” that should help combat the Circus Factor.
Still, there was much to be improved:
- App teams didn’t have real ownership of their services
- Our IaC was complex, which contributes to this lack of ownership
- Our deployment machinery was monolithic (a product of our services being homed in a monolithic repository). As we continued to scale, this imposed a ceiling on our deployment velocity
To solve these and more, we embarked on the next iteration of deployment and operations tooling at Freckle.
Why am I Excited?
We’re in the middle of a massive shift in the way Freckle delivers software. Historically, we’ve had homogeneous teams working on a single, shared backlog and developing in a monolithic repository that is deployed in a monolithic way. As mentioned, this only scales so far.
Inspired by Team Topologies, we’ve re-organized into stream-aligned persona-focused teams. Teams get a stronger sense of ownership, top to bottom. We want higher velocity through higher autonomy, decreased cross-team dependencies, and reduced cognitive load. This will create pressure to break our monolithic architecture down along the same lines (also known as the Inverse Conway Maneuver).
Supporting separate teams owning their own stacks motivated a new split between a “Freckle Platform” and the “Apps” deployed on it. To help our App teams deliver software on our Platform, we first built an internal tool called PlatformCLI.
All of this necessitated the transition of our traditional “Ops” team into a true Platform Team, serving internal personas (e.g. our App teams) as customers, and benefiting from all the product-delivery expertise we’ve acquired serving educators and students over the years.
Ideally, the Platform Team would “dog-food” their own tools to build and deploy the resources making up the Freckle Platform, but we quickly discovered PlatformCLI was the wrong tool: its key benefits for App teams (limited choice, guard rails) are anti-features for a team maintaining complex resources with high variability.
Then it hit us.
PlatformCLI is primarily for defining and using a set of “recipes”. Recipes that capture a decade of operational wisdom, establish guard rails, and provide safe defaults for common cases. Through PlatformCLI and these recipes, App teams can build and deploy their own services, overriding or extending in ways that are important for them. PlatformCLI ultimately generates the Parameters and Template, then runs a CloudFormation deploy using them.
We had always thought of PlatformCLI as primarily a deployment tool. We now realized it was less about deployment and more about generation. What if it generated the artifact that captured all the details required to deploy a CloudFormation Stack, but then left the rest to something else?
If the interface between PlatformCLI and this something else were human-maintainable files on disk, we’d expose a clear seam for more operations-focused teams to gain complete control over the definition of the resources being deployed. We could maximize that control by keeping the on-disk representation as close to “Vanilla CloudFormation” as possible, without burdening the App teams who remain shielded by the generation step. And with that something else extracted and used by both, it’ll see double the usage and mature that much faster.
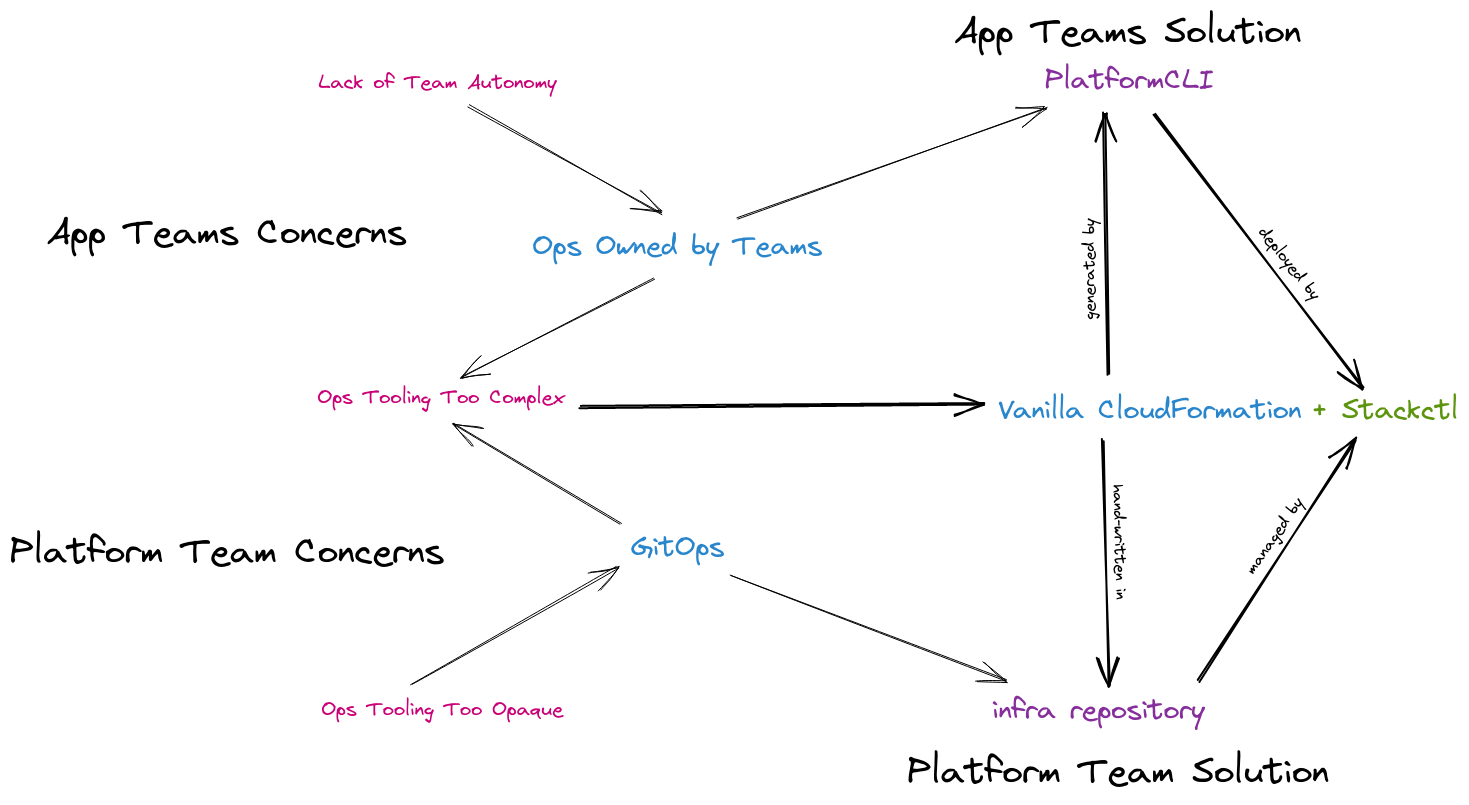
We made the connection to GitOps immediately. App teams would use PlatformCLI to generate and deploy their services, but the Platform Team could author the same on-disk representations by hand and commit them in git, and use the same tooling to deploy them automatically via GitHub Actions.
Specifying CloudFormation Stacks
A Stack Specification (StackSpec for short) is a file-system format2 that fully captures the deployed (or to-be-deployed) state of all your CloudFormation Stacks, across many Accounts or Regions:
./
stacks/
{account-id}.{account-name}/
{region}/
{name}.yaml
{namespace}/
{name}.yaml
{name}.yaml
{account-id}.{account-name}/
{region}/
{name}.yaml
templates/
{name}.yaml
{name}.yaml
{name}.yaml
Each file under stacks/ represents a Stack to be deployed into the Account and
Region that are its parent directories. That file will specify things like the
Parameters or Tags to deploy the Stack with, as well as the Template to
use, which would be a file under templates/. This makes the templates/ files
your unit of re-use, with many Stacks, across any number of Accounts or Regions,
using them with modified Parameters. For more details, see the
docs.
Since this deployment artifact is really just a collection of plain-text files, you’ll find all the benefits you expect: they’re editable with all the standard Unix tools, they can be checked into git. They can be diffed, updated, and rolled back, and all that via Pull Requests too. Automation can run when those changes are proposed or merged.
Notably though, this IaC is not C: a tree of Yaml3 does not a Code make.
This is a feature for us, not a bug. We spent years writing IaC in Haskell, the
code-est of code, and all it resulted in was a mess of hard-to-follow spaghetti.
We very much prefer declarative Templates and limiting our ability to re-use
them to the built-in CloudFormation facilities like Parameters, Mapping, and
Sub.
AWS CDK is a great tool offering many of the same benefits you are
reading about here. If you use and prefer that, that’s great. However, for us,
the fact that CDK is coding in a Real Programming Language ![]() means it’s a
non-starter for us.
means it’s a
non-starter for us.
Controlling Stacks with Stackctl
Once you have a directory of StackSpecs, you can use stackctl to manage them.
You can pretty-print them:

You can view any changes between the on-disk and deployed state:

And you can deploy changes:
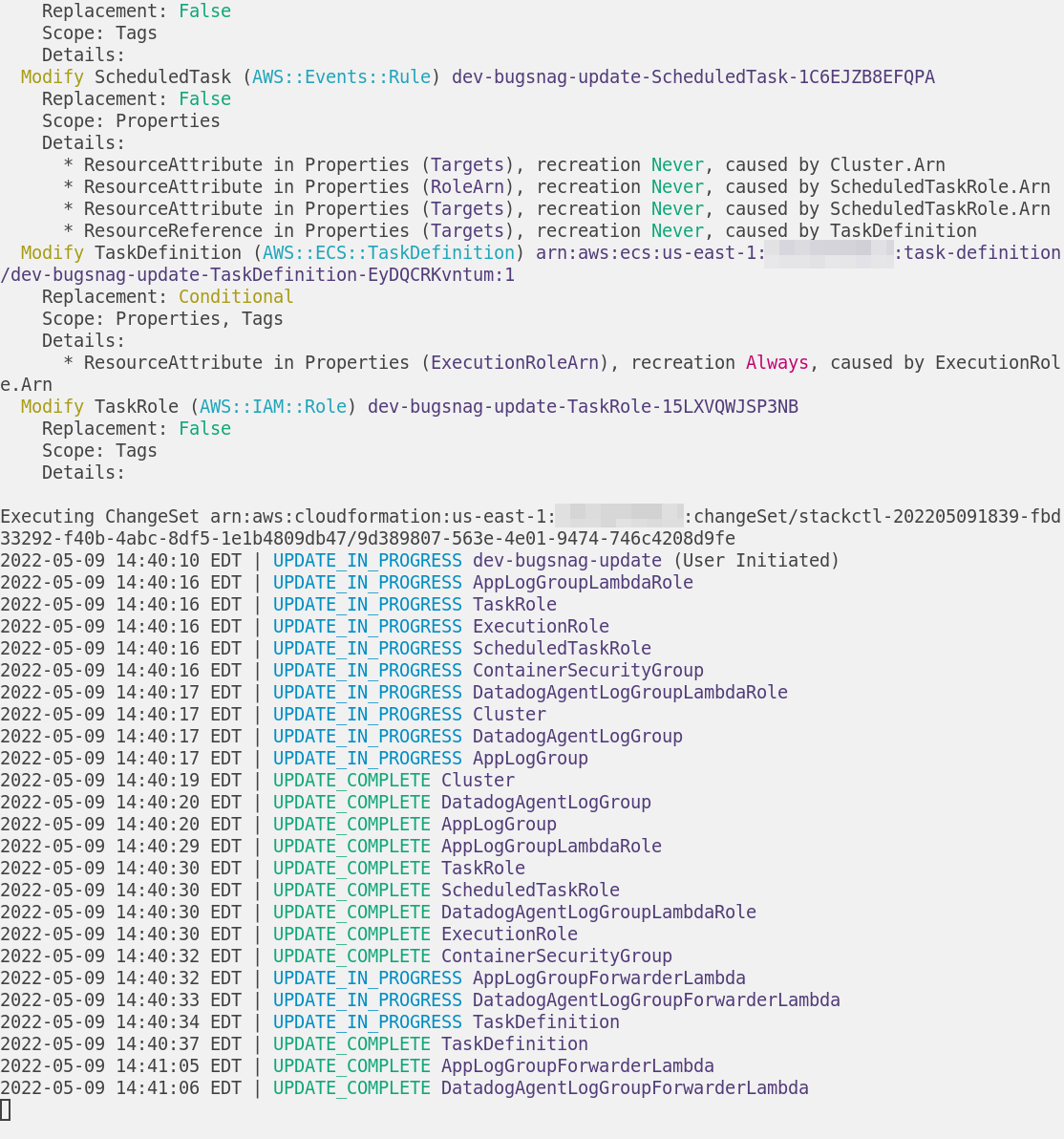
Installation includes completions and man pages to maximize discoverability:
Stackctl 🤝 Git(Hub)Ops
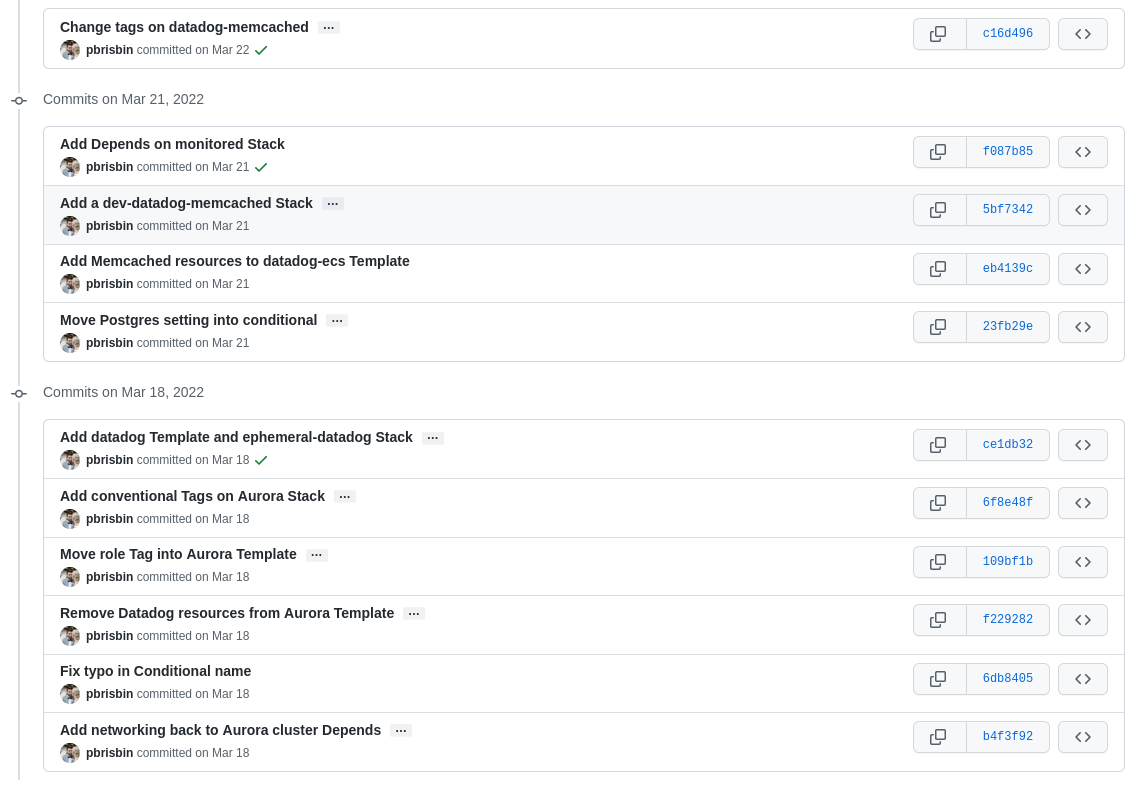
Our Platform Team is now using StackSpecs and a GitOps workflow to maintain their resources in a safe and transparent way. Ultimately, we end up with a valuable history of every infrastructure change made:
Trusting GitHub with deployment of your most critical resources is a risk. We take full advantage of various GitHub and AWS features to keep things as safe (both in a security sense and a mistake sense) as possible:
- We use Federated OIDC and ephemeral tokens, so we can avoid long-lived AWS Keys with high permissions sitting in this repository’s settings
- We enforce the maximum branch protection possible on
main: no direct pushes, Approval and Status Checks required, rebase merge from an up to date branch only, and new code dismisses reviews - We enforce these protections even for Admins of the repository
We’re really happy with these workflows, both for App teams and the Platform Team. We find our AWS resources are more discoverable, and experimenting with new Apps that still follow our best-practices is far easier than before. The Platform Team is enjoying the new “it’s just CloudFormation” approach with the quality of life improvements Stackctl brings, and maintaining infrastructure like anything else (through code reviews and auto-deploys) is a huge win.
Still, there is much to be improved.
-
Right now, these GitHub Actions are defined in the (private) repository itself. They aren’t doing too much, but we do hope to extract and open source them soon. ↩
-
This design is heavily inspired by the CloudGenesis project, though we’ve made some adjustments for our own use. ↩
-
Yes, we all hate Yaml. It is objectively full of loaded foot-guns, and we should all be using Dhall. We may move to that some day, but we decided to stick with the familiar for now. We also find that by parsing Yaml in a fully-typed language like Haskell, you actually avoid most of the pitfalls. ↩